目前为止,你已经知道如何定义神经网络、计算损失和更新网络的权重。现在你可能在想,那数据呢?
What about data?
通常,当你需要处理图像、文本、音频或者视频数据时,你可以使用标准Python包来将数据导入到numpy 数组中。然后再将数组转换成torch.Tensor。
- 对于图像,可用的包有:Pillow、OpenCV
- 对于音频,可用的包有:scipy和librosa
- 对于文本,无论是基于原始的Python或Cython的加载,或是NLTK和SpaCy都是可以的。
- 对于视频数据,PyTorch提供一个名为
torchvision的包,其中包含了常见数据集的数据加载器,像Imagenet、CIFAR10、MNISt等,以及图形数据转换器:torchvision.datasets和torch.utils.data.DataLoader。
这提供了极大的便利,同时避免编写样板代码。
在本教程中,我们使用CIFAR10数据集。它包含的分类有:飞机、汽车、鸟、猫 鹿、狗、青蛙、马、船和卡车。CIFAR-10中的图像尺寸是3x32x32,即32x32像素大小的3通道彩色图像。

训练一个图像分类器
要训练一个图像分类器,我们需要按步骤执行以下操作:
- 使用
torchvision加载和标准化CIFAR10训练和测试数据集 - 定义卷积神经网络
- 定义损失函数
- 使用训练数据训练网络
- 使用测试数据测试网络
1. 加载并标准化CIFAR10
使用torchvision很容易导入CIFAR10。
import torch
import torchvision
import torchvision.transforms as transforms
torchvision数据集的输出是范围在[0,1]之间的PILImage图像。我们需要将他们转换成标准化范围在[-1,1]之间的张量。
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=4, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'trunk')
输出:
Downloading http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Files already downloaded and verified
下面我们查看下部分训练图像:
import numpy as np
import matplotlib.pyplot as plt
def imshow(img):
# show an image
img = img / 2+0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 随机获取训练图像
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 输出图形
imshow(torchvision.utils.make_grid(images))
# 输出标签
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
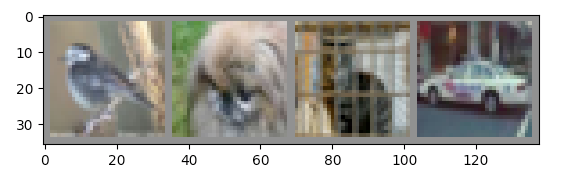
输出:
bird dog cat car
2. 定义卷积神经网络
复制之前神经网络章节中的神经网络定义,并修改为3通道图像。
import torch.nn.functional as F
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
3. 定义损失函数和优化
使用分类交叉熵损失函数和动量随机梯度下降。
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
4. 训练网络
接下来就是有趣的部分了。我们只需要循环迭代我们的数据,将输入提供给网络并进行优化。
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取输入值,data是一个[input,labels]的列表
inputs, labels = data
# 初始化参数的梯度
optimizer.zero_grad()
# 前向 + 反向 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计结构
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d,%5d] loss: %.3f' % (epoch + 1, i+1, running_loss/2000))
running_loss = 0.0
print('Finished Trainning')
输出:
[1, 2000] loss: 2.142
[1, 4000] loss: 1.964
[1, 6000] loss: 1.973
[1, 8000] loss: 1.957
[1,10000] loss: 1.941
[1,12000] loss: 1.960
[2, 2000] loss: 1.995
[2, 4000] loss: 2.019
[2, 6000] loss: 1.979
[2, 8000] loss: 2.006
[2,10000] loss: 2.015
[2,12000] loss: 1.997
Finished Trainning
5. 使用测试数据测试网络
我们已经训练了两此网络。但是我们需要检查网络是否已经学到了什么。
我们可以通过神经网络输出的类标签来检查这一点,并结合实际情况进行检查。如果预测正确,我们就将样本添加到正确的预测列表中。
现在,第一步,我们先从测试集中显示一些图片来方便比较:
dataiter = iter(testloader)
images, labels = dataiter.next()
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))

输出:
GroundTruth: cat ship ship plane
现在,我们看下神经网络觉得我们的例子是什么:
outputs = net(images)
输出是由10个类别的得分。类别的得分越高,神经网络就会预测图像是那个类。所以,我们现在获取得分最高的索引:
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
输出:
Predicted: car ship trunk plane
结果还不错。
接下来看看网络在整个测试集上的预测。
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
输出:
Accuracy of the network on the 10000 test images: 27 %
结果显然比随机,10%的准确率(随机从10个类别中取一个),高很多。看起来网络是学到了东西的。
那么,哪些类别预测得好,哪些类别预测得不好呢:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' %
(classes[i], 100*class_correct[i]/class_total[i]))
输出:
Accuracy of plane : 7 %
Accuracy of car : 53 %
Accuracy of bird : 9 %
Accuracy of cat : 2 %
Accuracy of deer : 57 %
Accuracy of dog : 41 %
Accuracy of frog : 3 %
Accuracy of horse : 38 %
Accuracy of ship : 33 %
Accuracy of trunk : 41 %
那么接下来做什么呢?在GPU上运行神经网络如何?
在GPU上训练
就像在CPU上训练张量一样,你可以将网络转移到GPU上。
如果我们有可用的CUDA的话,我们首先将我们的设备定义为第一个可见的cuda设备。
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
输出:
cuda:0
接下来的章节假定device是CUDA设备。
然后这些方法将递归遍历所有的模型并将参数和缓冲区转换为CUDA张量:
net.to(device)
注意,你还必须将每一步的输入和目标也转移到GPU上:
inputs, labels = data[0].to(device),data[1].to(device)

声明:本作品采用署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)进行许可,使用时请注明出处。
Author: mengbin
blog: mengbin
Github: mengbin92
cnblogs: 恋水无意