简介
Python是一种跨平台的编程语言。它是一种解释型、面向对象、动态数据类型的高级编程语言,它是由Guido van Rossum于1989年开发出来,遵循GPL协议。在2020年1月1日,Python官方宣布停止Python 2的更新,所以本教程使用Python 3.7.7。
Python有什么特点呢?
- 易于学习:Python的关键字相对较少,结构简单
- 易于阅读:Python的代码定义清晰,可读性性高
- 广泛的标准库:Python拥有丰富的库,跨平台,可以说,你能想到的功能,Python都有现成的库可供使用
那么Python可以做什么呢?
- 日常任务,比如定期备份资料;
- 做网站,国内的豆瓣,Google的Youtube,都是用Python写的;
- 也可以做网络游戏的后台;
- 等等
那么本教程适合哪些人群学习呢?
- 会使用电脑,但是从没写过程序;
- 想通过编程简化部分日常工作
- 每天可以抽出半小时左右时间学习
注:目前Python的最新版为3.11.0
环境搭建
本章节我们介绍如何搭建Python的开发环境。
考虑到本教程是面向编程基础为0的用户,所以这里就以Windows系统为例来搭建开发环境。
Python下载
有关Python的最新源码、二进制文件、文档等资讯都可以从Python官网获取。
本教程使用的Python3.7.7,可以从这里获取。

download
Python安装
Windows版的Python,遵循Windows系统一贯的傻瓜式的“Next”安装方式,安装步骤如下:
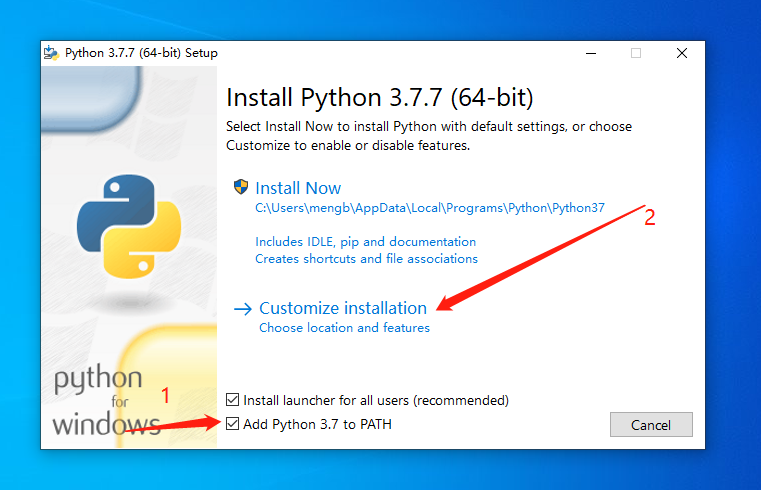
install_00

install_01
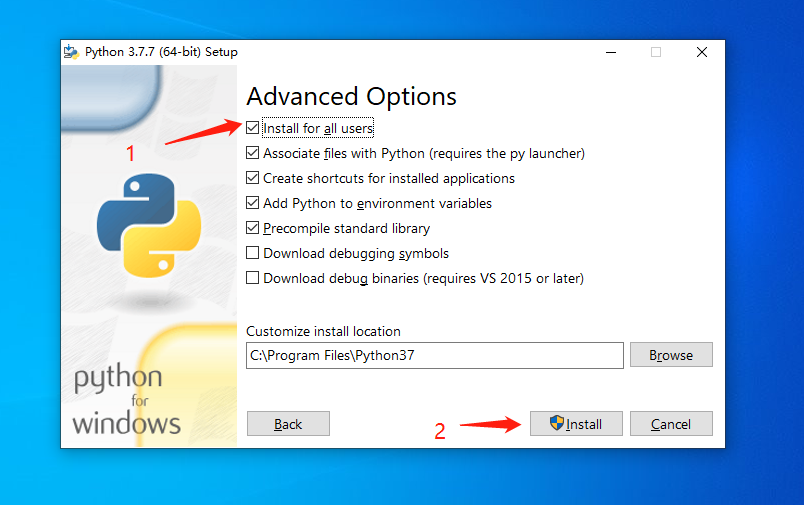
install_02
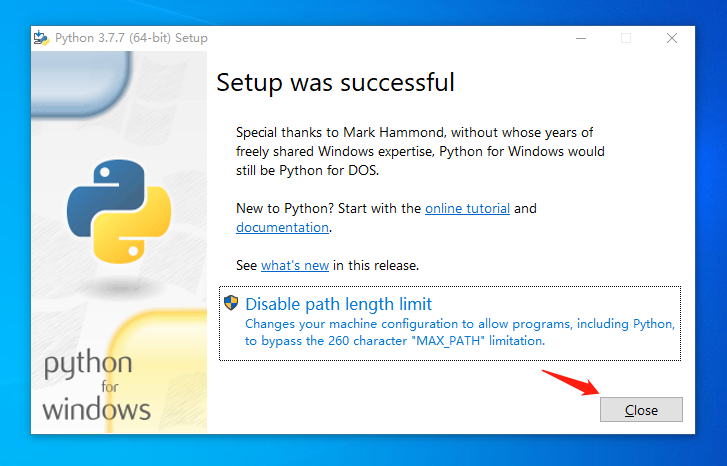
install_03
第一个Python程序
在Windows的左下角的搜索框中输入powershell,如下图:
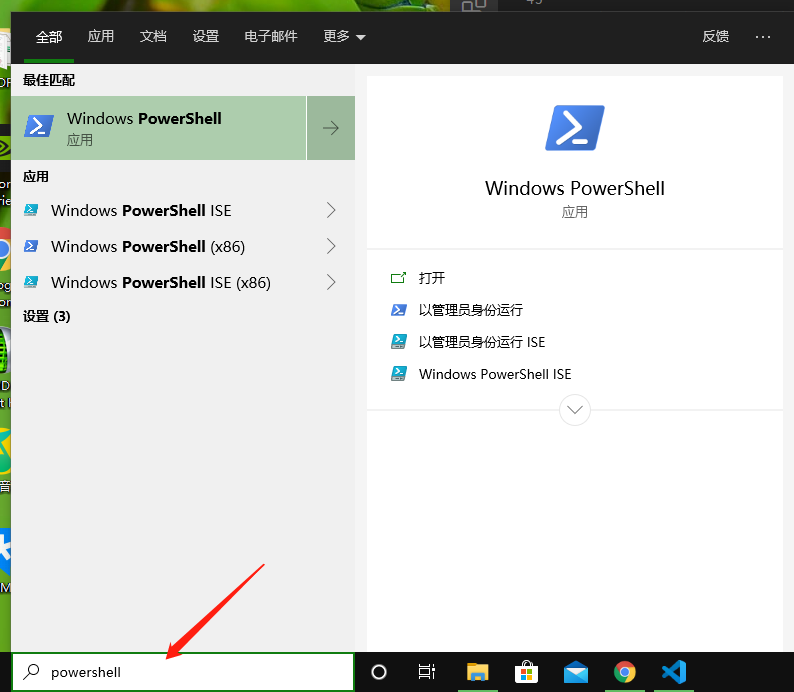
first_00
回车之后会打开一个黑窗口,在其中输入python,结果如下图:
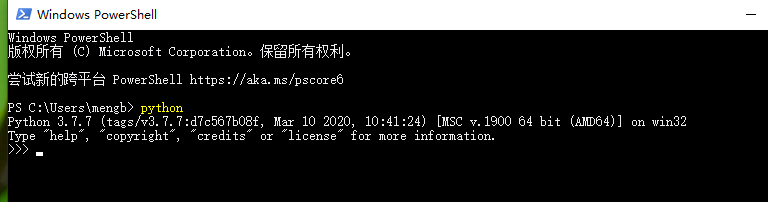
first_01
之后输入如下内容:
print('hello world')
得到下面的图:

first_02
选择合适的编辑器
对于编程而言,一个适合自己的编辑器能起到事半功倍的效果。这里推荐微软推出的跨平台的文本编辑器VSCode。
vscode可以从这里下载,选择如下:
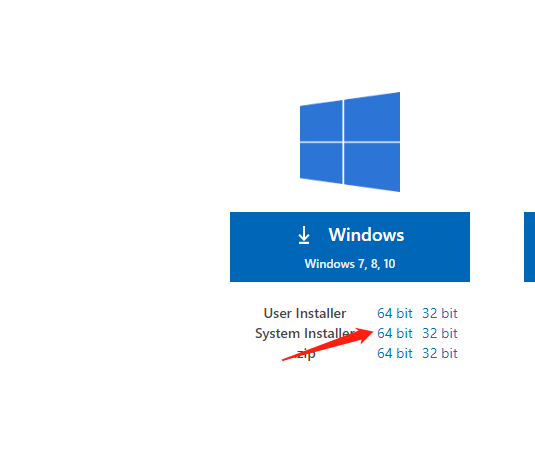
download_vscode
下载完成后双击安装即可。
配置vscode
安装完成后,打开vscode,操作如下:
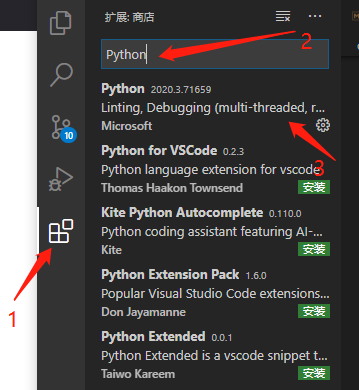
config_vscode
汉化vscode:

chinese_vscode
Python基础
Python作为一门计算机编程语言,它于我们日常使用的自然语言有所不同,最大的不同之处在于,自然语言在不同的语境中可以有不同的解释;但对于编程语言,计算机需要根据给定的编程语言执行相应的任务,这就必须保证编程语言所写的程序不能有歧义。所以每种编程语言都有自己的一套语法,编译器或解释器把符合语法规范的代码转换成CPU能够执行的二进制程序。
Python也有自己的语法,不过它的语法相对比较简单,采用缩进的方式作为语法规则,写出的代码格式就想下面的例子:
# 输出字符串 a 或者 b
a = '123'
b = '456'
if a != b:
print(a)
else:
print(b)
以#开头的语句为注释,是为了给人看的,可以是对接下来的代码的注释,也可以是一些调侃的话,代码执行的时候解释器会自动忽略掉这行的内容,所以#之后可以是任何内容。之后的每一行都是一个语句;当语句以:结尾时,下一行的语句必须进行缩进,这是一个代码块。按照约定俗称的惯例,缩进使用4个空格。最后,Python程序大小写敏感,即大小写代表不同的内容。
Python基本的数据类型
在Python中,变量不需要声明,但在使用之前必须进行赋值,变量赋值以后该变量才会被创建。
在Python中,变量赋值使用的是=,它表示把=右边的值赋值给左边的变量,而不是表示=左右两边相等。在编程语言中,通常用==来判断等号两边的变量是否相等。
在Python3中,有6个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Number
Python3支持int、float、bool、complex(复数)。跟其它的编程语言一样,数值类型的赋值和计算都是非常直观的。可以使用内置的type()来查询变量所指向的内容的数据类型。
>>> a,b = 100,200
>>> print(a,type(a),b,type(b))
100 <class 'int'> 200 <class 'int'>
Python的解释器可以像一个简单的计算器一样:你可以在里面输入一个表达式,之后它会写出答案:
>>> 5 + 4 #加法
9
>>> 5 * 4 #乘法
20
>>> 5 / 4 #除法,得到一个浮点数
1.25
>>> 5 / 4 #除法,得到一个整数
1
>>> 5 - 4 #减法
1
>>> 5 ** 2 # **表示计算幂运算
25
String
Python中的字符串用单引号'或者双引号"引起来,使用反斜杠\转义特殊字符:
>>> 'hello' # 等价于 "hello"
'hello'
>>> 'doesn\'t'
"doesn't"
>>> '"Yes," they said.'
'"Yes," they said.'
>>> "\"Yes,\" they said."
'"Yes," they said.'
当然,如果你不想使用\来转义特殊字符,可以在引号前加r来表示使用原始字符串输出:
>>> r'C:\some\name'
C:\\some\\name
当你想输入一行比较长的字符串时,可以使用"""..."""或'''...''',也可以在行尾使用\忽略字符串中包含的换行符:
print('''\
Usage: thingy [OPTIONS]
-h
-H hostname
''')
输出如下,最开始的空行并没有包含进来:
Usage: thingy [OPTIONS]
-h
-H hostname
字符串可以使用+来进行拼接,也可以使用*进行重复:
>>> 3 * 'un' + 'ium'
'unununium'
字符串可以被索引,即通过下标访问,索引值从0开始。
>>> word = 'Python'
>>> word[0]
'P'
>>> word[5]
'n'
索引值也可以是负的,表示从右开始索引:
>>> word[-1]
'n'
>>> word[-2]
'o'
>>> word[-6]
'P'
字符串不仅能被索引,还支持切片。索引得到的是单个字符,切片得到的是字符串的子串:
>>> word[0:2] # 前闭后开
'Py'
>>> word[2:5]
'tho'
如果索引值过大时,会产生一个错误:
>>> word[42]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
但切片的越界索引会被自动处理:
>>> word[4:42]
'on'
>>> word[42:]
''
当想知道一个字符串的大小时,可以使用内建的函数len()来计算:
>>> len(word)
6
列表
在Python中除了前面介绍的三种基础类型之外,还有多种复合数据类型,其中最常用的就是列表,它是一组由方括号扩起、逗号分隔的一组元素组成。一个列表中可以包含不同数据类型的元素,不过使用时通常使用的各个元素类型相同:
>>> squares = [1, 3, 4, 5, 0]
>>> squares
[1, 3, 4, 5, 0]
跟字符串一样,列表也支持索引和切片:
>>> squares[0]
1
>>> squares[-1]
0
>>> squares[-3:]
[4, 5, 0]
列表也支持拼接操作:
>>> squares + [2, 4, 5, 54, 65]
[1, 3, 4, 5, 0, 2, 4, 5, 54, 65]
你也可以通过append()方法来在列表的末尾添加一个新的元素:
>>> squares.append(9)
[1, 3, 4, 5, 0, 9]
也可以使用len()来获取列表的长度:
>>> letters = ['a', 'b', 'c', 'd']
>>> len(letters)
4
元组
元组是由多个被逗号分隔的值组成的(注意,这里没有说用方括号括起来),比如:
>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
>>> # Tuples are immutable:
... t[0] = 88888
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> # but they can contain mutable objects:
... v = ([1, 2, 3], [3, 2, 1])
>>> v
([1, 2, 3], [3, 2, 1])
如你所见,元组在输出的时候总是被小括号括起来,以便正确表示嵌套元组。输入时的小括号虽然可有可无,但最好还是加上。
集合
Python中也包含集合类型。集合是由不重复元素组成的无序的集。它的基本用法包括成员检测和消除重复元素。集合对象也支持像 联合,交集,差集,对称差分等数学运算。
花括号或set()函数可以用来创建集合。注意,要创建一个空集合,只能使用set(),不能用{},因为{}是创建一个空的字典。
下面是集合的一些简单示例:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}
字典
字典是Python中非常有用的内置数据类型。与字符串、列表这些以连续整数为索引的序列不同,字典是一种以key为索引的数据结构,key的值可以是任意不可变的类型,通常是字符串或数字。
字典可以看作是一个key:value的集合,key值必须是唯一的。一对空的大括号可以创建一个空字典:{}。常见的字典初始化方式是在一对大括号中放一些以逗号隔开的键值对,这也是字典的输出方式。
字段主要的操作是使用关键字存储和解析值。也可以使用del来删除一个键值对。如果你使用一个已经存在的关键字来存储值,那么之前存储的值就会被舍弃。用一个不存在的键来取值则会报错。
对一个字典执行list(d)将返回包含该字典中所有键的列表,按照插入顺序排序;要按照其它排序,使用sorted(d)。
下面是一些字典的简单示例:
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'jack': 4098, 'sape': 4139, 'guido': 4127}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'jack': 4098, 'guido': 4127, 'irv': 4127}
>>> list(tel)
['jack', 'guido', 'irv']
>>> sorted(tel)
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
>>> 'jack' not in tel
False
dict()构造函数可以直接从键值对序列里创建字典:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'guido': 4127, 'jack': 4098}
Python 运算符
算数运算符
| 运算符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取模,即余数 |
| ** | 幂运算 |
| // | 整除,向下取商 |
>>> a, b = 21, 10
>>> a + b
31
>>> a - b
11
>>> a * b
210
>>> a / b
2.1
>>> a % b
1
>>> 2 ** 3
8
>>> a // b
2
比较运算符
| 运算符 | 描述 |
|---|---|
| == | 等于 |
| != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
>>> a, b = 21, 10
>>> a == b
False
>>> a != b
True
>>> a > b
True
>>> a < b
False
>>> a >= b
False
>>> a <= b
>>> False
赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 简单的赋值 |
| += | 加法赋值运算 |
| -= | 减法赋值运算 |
| *= | 乘法赋值运算 |
| /= | 除法赋值运算 |
| %= | 取模赋值运算 |
| **= | 幂赋值运算 |
| //= | 取整赋值运算 |
>>> a, b = 21, 10
>>> c = a + b
>>> c
31
>>> c += a; print(c)
52
>>> c -= a; print(c)
31
>>> c *= a; print(c)
651
>>> c /= a; print(c)
31.0
>>> c %= a; print(c)
10.0
>>> c //= a; print(c)
0.0
>>> c = 2; c **= a; print(c)
2097152
成员运算符
| 运算符 | 描述 |
|---|---|
| in | 如果在指定的序列中找到值返回True,否则返回False |
| not in | 如果在指定的序列中找不到值返回True,否则返回False |
>>> a = 10
>>> b = 2
>>> ls = [1, 2, 3, 4, 5]
>>> a in ls
False
>>> a not in ls
True
>>> b in ls
True
>>> b not in ls
False
条件控制
Python的条件控制是通过一条或者多条语句的结果(True或False)来决定将要执行的代码,下图可以简单的表示条件语句的执行过程:
st=>start: Start
op1=>operation: Operation1
op2=>operation: Operation2
op3=>operation: Operation3
op4=>operation: Operation4
op5=>operation: Operation5
cond1=>condition: yes or no
cond2=>condition: yes or no
st->op1->cond1
cond1(yes)->op2
st->op1->cond1
cond1(no)->op3->cond2
cond2(yes)->op4
cond2(no)->op5
示例如下:
password = '123456'
pw1 = input('请输入密码:')
if pw1 == '':
print('输入不能为空')
elif pw1 == password:
print('登录成功')
else:
print('密码错误')
循环语句
for循环
for循环可以用来遍历任何序列项目,比如一个列表或一个字符串。一般流程如下:
graph TD
A[开始] --> B{序列中的元素} --> C[代码块] --> B
B --> D[结束]
示例如下:
>>> string = 'abcdef'
>>> for c in string:
... print(c)
...
a
b
c
d
e
f
while循环
graph TD
A[开始循环] --> B{判定条件} --条件为真--> C[代码块] --> B
B --条件不成立--> D[结束循环]
在for循环中,可以使用break来跳出循环:
示例如下
>>> a = 1
>>> while a < 10:
... print(a)
... a += 4
...
1
5
9
range()函数
如果你需要遍历一个数字序列,可以使用内置的range()函数,它生成算术级数:
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
给定的终止数值不在生成的序列中。range也可以以一个数字开头,另一个数字结尾(也可以指定增加的幅度),也可以使用负数:
range(5, 10)
5, 6, 7, 8, 9
range(0, 10, 3)
0, 3, 6, 9
range(-10, -100, -30)
-10, -40, -70
break 和 continue语句
break语句用于跳出最近的for或while循环。循环语句可能带有一个 else 子句;它会在循环遍历完列表 (使用 for) 或是在条件变为假 (使用 while) 的时候被执行,但是不会在循环被 break 语句终止时被执行。 这可以通过以下搜索素数的循环为例来进行说明:
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0:
... print(n, 'equals', x, '*', n//x)
... break
... else:
... # loop fell through without finding a factor
... print(n, 'is a prime number')
...
2 is a prime number
3 is a prime number
4 equals 2 * 2
5 is a prime number
6 equals 2 * 3
7 is a prime number
8 equals 2 * 4
9 equals 3 * 3
coutinue语句表示继续循环中的下一次迭代:
>>> for num in range(2, 10):
... if num % 2 == 0:
... print("Found an even number", num)
... continue
... print("Found a number", num)
Found an even number 2
Found a number 3
Found an even number 4
Found a number 5
Found an even number 6
Found a number 7
Found an even number 8
Found a number 9
pass语句
pass语句表示什么也不做。通常用在语法上需要一个语句,但程序需要什么也不做的情况下:
>>> while True:
... pass # Busy-wait for keyboard interrupt (Ctrl+C)
...
函数
函数是一段组织好的、可重复使用的、用来实现单一或相关功能的代码段,它可以提高应用的模块性和代码的重复利用率。
之前用来输出消息的print(),就是Python内建的用于输出消息的函数。当然你也可以自定义自己的函数。下面我们定义一个可以输出任意范围内的Fibonacci数列的函数:
>>> def fib(n): # write Fibonacci series up to n
... """Print a Fibonacci series up to n."""
... a, b = 0, 1
... while a < n:
... print(a, end=' ')
... a, b = b, a+b
... print()
...
>>> # Now call the function we just defined:
... fib(2000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
关键字def引入一个函数 定义。它必须后跟函数名称和带括号的形式参数列表。构成函数体的语句从下一行开始,并且必须缩进。
函数定义的更多形式
默认参数
函数定义最有用的形式是对一个或多个参数指定一个默认值。这样创建的函数,可以用比定义时更少的参数调用,比如:
def ask_ok(prompt, retries=4, reminder='Please try again!'):
while True:
ok = input(prompt)
if ok in ('y', 'ye', 'yes'):
return True
if ok in ('n', 'no', 'nop', 'nope'):
return False
retries = retries - 1
if retries < 0:
raise ValueError('invalid user response')
print(reminder)
这个函数可以通过几种方式调用:
- 只给出必需的参数:
ask_ok('Do you really want to quit?') - 给出一个可选的参数:
ask_ok('OK to overwrite the file?', 2) - 或者给出所有的参数:
ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!')
关键字参数
也可以使用类似kwarg=value的关键字参数来调用函数,例如下面的函数:
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):
print("-- This parrot wouldn't", action, end=' ')
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
函数需要一个必需的参数voltage和三个可选参数state、action和type。这个函数可以通过下面的任何一种方式调用:
parrot(1000) # 1 positional argument
parrot(voltage=1000) # 1 keyword argument
parrot(voltage=1000000, action='VOOOOOM') # 2 keyword arguments
parrot(action='VOOOOOM', voltage=1000000) # 2 keyword arguments
parrot('a million', 'bereft of life', 'jump') # 3 positional arguments
parrot('a thousand', state='pushing up the daisies') # 1 positional, 1 keyword
但下面的函数调用都是无效的:
parrot() # required argument missing
parrot(voltage=5.0, 'dead') # non-keyword argument after a keyword argument
parrot(110, voltage=220) # duplicate value for the same argument
parrot(actor='John Cleese') # unknown keyword argument
在函数调用中,关键字参数必须跟随在位置参数的后面。传递的所有关键字参数必须与函数接受的其中一个参数匹配(比如actor不是函数parrot的有效参数),它们的顺序并不重要。这也包括非可选参数,(比如parrot(voltage=1000)也是有效的)。不能对同一个参数多次赋值。
参数传递
在python中,类型属于对象,变量是没有类型的。
在python中,字符串、元组和数字是不可更改的对象,列表和字典则是可以修改的对象。
- 不可变对象:变量赋值
a=5后再赋值a=10,这里实际是新生成一个int对象10,然后再让a指向它,之前的5会被丢弃。这相当于是新生成了个a,而不是改变了它的值。 - 可变对象:变量赋值
ls = [1,2,3,4,5],然后赋值ls[2] = 9;这只是修改了第三个元素的值,ls本身并没有改动。
python函数的参数传递:
- 不可变类型:对于不可变类型,传递参数时,实际是将参数的值传递到函数内部,并不是参数本身,相当于只是传了一个该参数的复本到函数中。
- 可变类型:对于可变类型,传递参数时,是将参数本身传递给了函数,在函数中的修改会影响到参数本身。
return语句
return [表达式]语句用于退出函数,选择向调用者返回一个表达式。之前的例子都是没有返回值的,下面是有返回值的,同样是以Fibonacci为例:
>>> def fib2(n): # return Fibonacci series up to n
... """Return a list containing the Fibonacci series up to n."""
... result = []
... a, b = 0, 1
... while a < n:
... result.append(a) # see below
... a, b = b, a+b
... return result
...
>>> f100 = fib2(100) # call it
>>> f100 # write the result
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
模块
之前的例子都是在Python解释器中执行的,如果你退出再进入,那么之前定义的所有内容都会消失。因此,如果你想要编写一个稍长些的程序,最好使用文本编辑器为编译器准备好输入并将该文件作为输入运行。这个过程通常被称为编写脚本。随着程序变得越来越长,你或许会想把它拆分成几个文件,以方便维护。亦或你想在不同的程序中使用一个便捷的函数,而不是把这个函数复制到每一个程序中去。
为支持这些,Python提供了一种方法:可以把定义放在一个文件里,并在脚本或解释器的交互式实例中使用它们。这样的文件被称作模块;模块中的定义可以导入到其它模块或者主模块(你在顶级和计算器模式下执行的脚本中可以访问的变量集合)。
模块是一个包含Python定义和语句的文件。文件名通常就是模块名后跟Python文件后缀.py。在模块内部,模块名可以通过全局变量__name__的值来获取。例如,你可以把之前的两个关于Fibonacci的例子放在一个名为fibo.py文件中,示例如下:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
print()
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
现在打开Python解释器,输入以下命令导入该模块:
>>> import fibo
之后你可以通过模块名fibo来调用其中的函数:
>>> fibo.fib(1000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'
如果你要经常使用某个函数,你可以把它赋值给一个局部变量,以便之后使用:
>>> fib = fibo.fib
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
import的变式
上面介绍的只是导入模块的一种方式,接下来介绍另一种导入模块的方式:from ... import。
在Python中,from语句允许你导入模块中的一部分到当前环境中,例如:
>>> from fibo import fib, fib2
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种方式并不会把被调模块名引入到局部变量表中(因此在这个例子中,fibo是为定义的)。
import还有一个变式是导入模块中的所有定义:
>>> from fibo import *
>>> fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
但通常都不会使用这种方式,因为这可能会覆盖一些你定义过的东西,而且这种方式也会降低代码的可读性。
别名
那当导入的模块名称很长或者比较复杂的时候,有没有什么简单的方法来解决呢?答案当然是有的!
Python中的关键字as可以解决这一问题。在模块名之后使用as,那么as之后的名称可以当作导入模块的别名来绑定该模块中的所有定义:
>>> import fibo as fib
>>> fib.fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这种方法也能用在from变式中。
标准模块
Python附带了一个标准模块库,在单独的文档Python库参考中进行了描述。一些模块内置于解释器中;它们提供对不属于语言核心但仍然内置的操作的访问,以提高效率或提供对系统调用等操作系统原语的访问。这些模块的集合是一个配置选项,它也取决于底层平台。例如winreg模块只在Windows操作系统上提供。一个特别值得注意的模块sys,它被内嵌到每一个Python解释器中。变量sys.ps1和sys.ps2定义用作主要和辅助提示的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Yuck!')
Yuck!
C>
这两个变量只有在编译器是交互模式下才被定义。
输入输出
好的输入输出格式,可以方便阅读。
格式化
格式化字符串文字
格式化字符串字面值能让你在字符串前加上f和F并将表达式写出{expression}来在字符串中包含Python表达式的值。
可选的格式说明符可以跟在表达式后面。这样可以更好地控制值的格式化方式。下面是将$\pi$舍入到小数点后三位的例子:
>>> import math
>>> print(f'The value of pi is approximately {math.pi:.3f}.')
The value of pi is approximately 3.142.
在:后传递一个整数可以让该字段成为最小字符宽度。这在使列对齐时很有用。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
>>> for name, phone in table.items():
... print(f'{name:10} ==> {phone:10d}')
...
Sjoerd ==> 4127
Jack ==> 4098
Dcab ==> 7678
其它的修饰符可用于在格式化之前转化值。!a应用ascii(),!s应用str(),!r应用repr():
>>> animals = 'eels'
>>> print(f'My hovercraft is full of {animals}.')
My hovercraft is full of eels.
>>> print(f'My hovercraft is full of {animals!r}.')
My hovercraft is full of 'eels'.
字符串的format()方法
str.format()方法的基本用法如下所示:
>>> print('We are the {} who say "{}!"'.format('knights', 'Ni'))
We are the knights who say "Ni!"
大括号和其中的字符将替换为传递给str.format()方法的对象。大括号中的数字可用来表示传递给str.format()方法的对象的位置。
>>> print('{0} and {1}'.format('spam', 'eggs'))
spam and eggs
>>> print('{1} and {0}'.format('spam', 'eggs'))
eggs and spam
如果在str.format()方法中使用关键字参数,则使用参数的名称引用它们的值。
>>> print('This {food} is {adjective}.'.format(
... food='spam', adjective='absolutely horrible'))
This spam is absolutely horrible.
位置和关键字参数可以任意组合:
>>> print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',
other='Georg'))
The story of Bill, Manfred, and Georg.
如果你有一个非常长的格式字符串,你不想把它拆开,那么你最好按名称而不是位置引用变量来进行格式化。这可以通过简单地传递字典和使用方括号[]访问键来完成:
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; '
... 'Dcab: {0[Dcab]:d}'.format(table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
这也可以通过使用**符号将table作为关键字参数传递。
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
>>> print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
这在与内置函数vars()结合使用时非常有用,它将返回包含所有局部变量的字典。
例如,下面几行代码生成一组整齐的列,其中包含给定的整数和它的平方以及立方:
>>> for x in range(1, 11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
读写文件
open()返回一个file object,最常用的有两个参数:open(filename, mode)。
>>> f = open('workfile', 'w')
第一个参数是包含文件名的字符串。第二个参数是另一个字符串,其中包含一些描述文件使用方式的字符。mode可以是r,表示文件只能读取,w 表示只能写入(已存在的同名文件会被删除),还有a表示打开文件以追加内容;任何写入的数据会自动添加到文件的末尾。r+'表示打开文件进行读写。mode参数是可选的;省略时默认为r。
通常文件是以text mode打开的,这意味着从文件中读取或写入字符串时,都会以指定的编码方式进行编码。如果未指定编码格式,默认值与平台相关 (参见open())。在mode中追加的b则以binary mode打开文件:现在数据是以字节对象的形式进行读写的。这个模式应该用于所有不包含文本的文件。
在文本模式下读取时,默认会把平台特定的行结束符 (Unix 上的\n, Windows 上的\r\n) 转换为\n。在文本模式下写入时,默认会把出现的\n转换回平台特定的结束符。这样在幕后修改文件数据对文本文件来说没有问题,但是会破坏二进制数据例如JPEG或EXE文件中的数据。请一定要注意在读写此类文件时应使用二进制模式。
在处理文件对象时,最好使用with关键字。优点是当子句体结束后文件会正确关闭,即使在某个时刻引发了异常。而且使用with相比等效的try-finally代码块要简短得多:
>>> with open('workfile') as f:
... read_data = f.read()
>>> f.closed
True
如果你没有使用with关键字,那么你应该调用f.close()来关闭文件并立即释放它使用的所有系统资源。如果你没有显式地关闭文件,Python的垃圾回收器最终将销毁该对象并为你关闭打开的文件,但这个文件可能会保持打开状态一段时间。另外一个风险是不同的Python实现会在不同的时间进行清理。
通过with语句或者调用f.close()关闭文件对象后,尝试使用该文件对象将自动失败:
>>> f.close()
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: I/O operation on closed file.
文件对象的方法
假设你已经创建名为f的文件对象。
要读取文件的内容,可以使用f.read(size),它会读取一些数据并将其作为字符串(在文本模式下)或字节串对象(二进制模式下)返回。size是一个可选的数值参数。当size被省略或为负数时,将读取并返回整个文件的内容;如果文件的大小是你的机器内存的两倍就会出现问题。当取其他值时,将读取并返回至多size个字符(在文本模式下)或size个字节(在二进制模式下)。如果已到达文件末尾,f.read()将返回一个空字符串 ('')。
>>> f.read()
'This is the entire file.\n'
>>> f.read()
''
f.readline()从文中读取一行;换行符(\n)留在字符串的末尾。如果文件不以换行符结尾,则在文件的最后一行省略,这使得返回值明确无误。如果f.readline()返回一个空的字符串,则表示已经到达了文件末尾,而空行使用\n表示,表示只包含一个换行符:
>>> f.readline()
'This is the first line of the file.\n'
>>> f.readline()
'Second line of the file\n'
>>> f.readline()
''
要从文件中读取行,你可以循环遍历文件对象。这是内存高效,快速的,并简化代码:
>>> for line in f:
... print(line, end='')
...
This is the first line of the file.
Second line of the file
如果你想以列表的形式读取文件中的所有行,你也可以使用list(f)或f.readlines()。
f.write(string)会把string的内容写入到文件中,并返回写入的字符数:
>>> f.write('This is a test\n')
15
在写入其它类型的对象之前,需要先把它们转化为字符串(文本模式下)或者字节对象(二进制模式下):
>>> value = ('the answer', 42)
>>> s = str(value) # convert the tuple to string
>>> f.write(s)
18
f.tell()返回一个整数,给出文件对象在文件中的当前位置,表示为二进制模式下时从文件开始的字节数,以及文本模式下的意义不明的数字。
要改变文件对象的位置,可以使用f.seek(offset,whence)。通过向一个参考点添加offset来计算位置;参考点由whence参数指定。 whence的0值表示从文件开头起算,1表示使用当前文件位置,2表示使用文件末尾作为参考点。 whence如果省略则默认值为0,即使用文件开头作为参考点。
>>> f = open('workfile', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # Go to the 6th byte in the file
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # Go to the 3rd byte before the end
13
>>> f.read(1)
b'd'
Python进阶
类
在介绍类之前,需要先介绍下面向对象编程 — Object Oriented Programming,简称OOP,这是一中程序设计思想。在OOP中,把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
面向对象的程序设计把程序看作是一组对象的集合,每个对象都可以接受其它对象发过来的消息并进行处理。程序的执行实质是一系列消息在不同对象之间的传递处理。
这里有必要提一下面向过程编程 — Procedure Oriented Programming,检查POP。面向过程的程序设计是把程序看作一系列命令的集合,即一组函数的顺序执行。
Python从设计之初就是一门面向对象编程的语言,所以它同样具有面向对象编程的所有标准特性:类继承机制允许多个基类,派生类可以重写它基类的任何方法,一个方法可以调用基类中的同名方法。
接下来我们通过一个简单的例子来介绍面向对象编程和面向函数编程的不同。
假设我们要用程序来展示个人信息,包括姓名、年龄,在面向过程的程序中可能要用一个字典来表示:
person0 = {'name': 'xiaohong', 'age': '18'}
person1 = {'name': 'xiaoming', 'age': '20'}
而要展示个人信息,我们需要定义一个函数:
def print_person(person):
print('name: %s ,age: %d' % (persion['name'], person['age']))
在面向对象编程中,我们首先考虑的不是程序的执行过程,而是将person作为一个对象,这个对象有两个属性name和age,要展示这两个属性,需要一个print_person的方法来将这两个输出输出:
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def print_person(self):
print('name: %s ,age: %d' % (persion['name'], person['age']))
面向对象编程的程序类似下面的:
person0 = Person('xiaohong', 18)
person1 = Person('xiaoming', 20)
person0.print_person()
person1.print_person()
从上面的例子中,可以看出类提供了一种组合数据和功能的方法。创建一个新类意味着创建一个新的对象的类型,从而允许创建一个该对象的新实例。每个类的实例可以拥有保存自己状态的属性。一个类的实例也可以通过类中定义的方法来修改自己的状态。
pip包
除了Python提供的标准库之外,还有很多第三方开发者提供的包。你可以使用pip来安装、升级和移除软件包。默认情况下pip会从Python Package Index来安装软件包。
安装包
可以使用pip install packagename来安装最新版本的包,例如:
$ pip install novas
也可以在包名后跟==和版本号来安装特定版本的包:
$ pip install requests==2.6.0
更新包
你可以使用如下命令来更新软件包:
$ pip install --upgrade requests
卸载包
你可以使用如下命令来卸载指定的软件包:
$ pip uninstall requests
类
类提供了一种组合数据和功能的方法。创建一个新类意味着创建了一个新的对象类型,之后可以创建一个该类型的实例。每个类的实例可以拥有保存自己状态的属性,当然也可以通过在类中定义的方法来改变自己的属性。
作用域和命名空间
在介绍类之前,你需要先了解一些Python的作用域规则。
示例
Python读写excel文件
这里以个人信息汇总为例:疫情期间,公司A为了正常复工后的员工安全,在复工前期需要统计员工在个人信息以及假期的出行,公司人事在公司大群里发了份《员工个人信息反馈表》,表格内容如下:
| 序号 | 部门 | 姓名 | 目前所在地 | 是否返回 | 返程方式 | 返程时间 |
|---|---|---|---|---|---|---|
| 1 | dep1 | 张三 | 北京 | 否 | 无 | 10-11-16 |
员工填写完成后,统一发给人事,由人事统计后向老板汇报。
上面的例子中,主要涉及到对excel表格的读写。这里我们使用openpyxl来进行excel文件的读写。
首先,我们需要先安装openpyxl包:
pip install openpyxl
接着,我们需要构建一些员工的个人信息,然后将所有的文件放到当前目录下,整理到一个excel文件中:
import random
import datetime
from openpyxl import Workbook
'''
@param filename:生成的excel文件名
'''
def CreateExcel(filename):
# 创建文件对象
wb = Workbook()
# 获取一个sheet
firstSheet = wb.active
# 写入内容
# 这里选择使用append()方法,该方法直接将列表作为一行添加到execl中,列表中的每个元素存入一个一个单元格
firstSheet.append(titles)
# 按单元格写入excel
# 由于上面已经写入了一行内容,所以这里从第2行开始
firstSheet['A2'] = 1
'''
random.randint(1, 10) 返回1到10之间的整数
'''
firstSheet['B2'] = '部门'+str(random.randint(1, 10))
firstSheet['C2'] = 'name'+str(random.randint(1, 10))
firstSheet['D2'] = '地址'+str(random.randint(1, 10))
if random.randint(0, 3000) % 2 == 0:
firstSheet['E2'] = '是'
else:
firstSheet['E2'] = '否'
firstSheet['F2'] = ways[random.randint(1, 9999) % 3]
'''
datetime.date.today() 获取当前日期,
strftime('%Y-%m-%d') 格式化为“年-月-日”格式的字符串
'''
firstSheet['G2'] = datetime.date.today().strftime('%Y-%m-%d')
# 保存
wb.save(filename)
'''
@param files: 要汇总的excel文件列表
@param filename: 汇总后的excel文件名
'''
def CountExcel(files, filename):
# 打开文件对象
wb = Workbook()
# 获取一个sheet
ws = wb.active
# 写入表头
ws.append(titles)
i = 1
for name in files:
# 打开已存在的文件
wbTmp = load_workbook(name)
wsTmp = wbTmp.active
rows = []
# 迭代获取sheet中的所有行
for row in wsTmp.iter_rows():
rows.append(row)
# 为序号赋值
rows[1][0].value = i
# 因为每个excel表都只有两行,且第一行为表头,所以这里直接取第2行中的单元格的值
cells = []
for r in rows[1]:
cells.append(r.value)
ws.append(cells)
i += 1
wb.save(filename)
if __name__ == "__main__":
import os
# 删除当前目录下的total.xlsx
if os.path.exists('total.xlsx'):
os.remove('total.xlsx')
# 生成200个excel文件
for i in range(1, 201):
CreateExcel(str(i)+'.xlsx')
excels = []
# 遍历当前文件夹,获取目录下的所有excel文件
for filepath, dirname, filenames in os.walk(r'.'):
# 根据后缀来判断excel
for filename in filenames:
if os.path.splitext(filename)[-1] == '.xlsx':
excels.append(filename)
# 将所有的excel文件整合成一个文件
CountExcel(excels, 'total.xlsx')
# for excel in excels:
# os.remove(excel)
参考
本文是参照Python 3.7教程文档,结合我自己的使用过程编写的。
声明:本作品采用署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)进行许可,使用时请注明出处。
Author: mengbin92
Github: mengbin92
cnblogs: 恋水无意